
高性能计算并行宇宙:CUDA 初探
写 CS149 需要用到 CUDA,所以先简单学习一下 CUDA 的基础知识。
1 CUDA Introduction
CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的并行计算平台和编程模型,使得开发者可以利用 GPU 的并行计算能力,加速程序的运行。
要想写好 CUDA,首先要了解 CUDA 的编程模型。在 CUDA 中通常将 CPU 及内存称为主机(Host),GPU 和显存称为设备(Device),Host 通过调用函数(Kernel)将任务分配给 Device 执行。
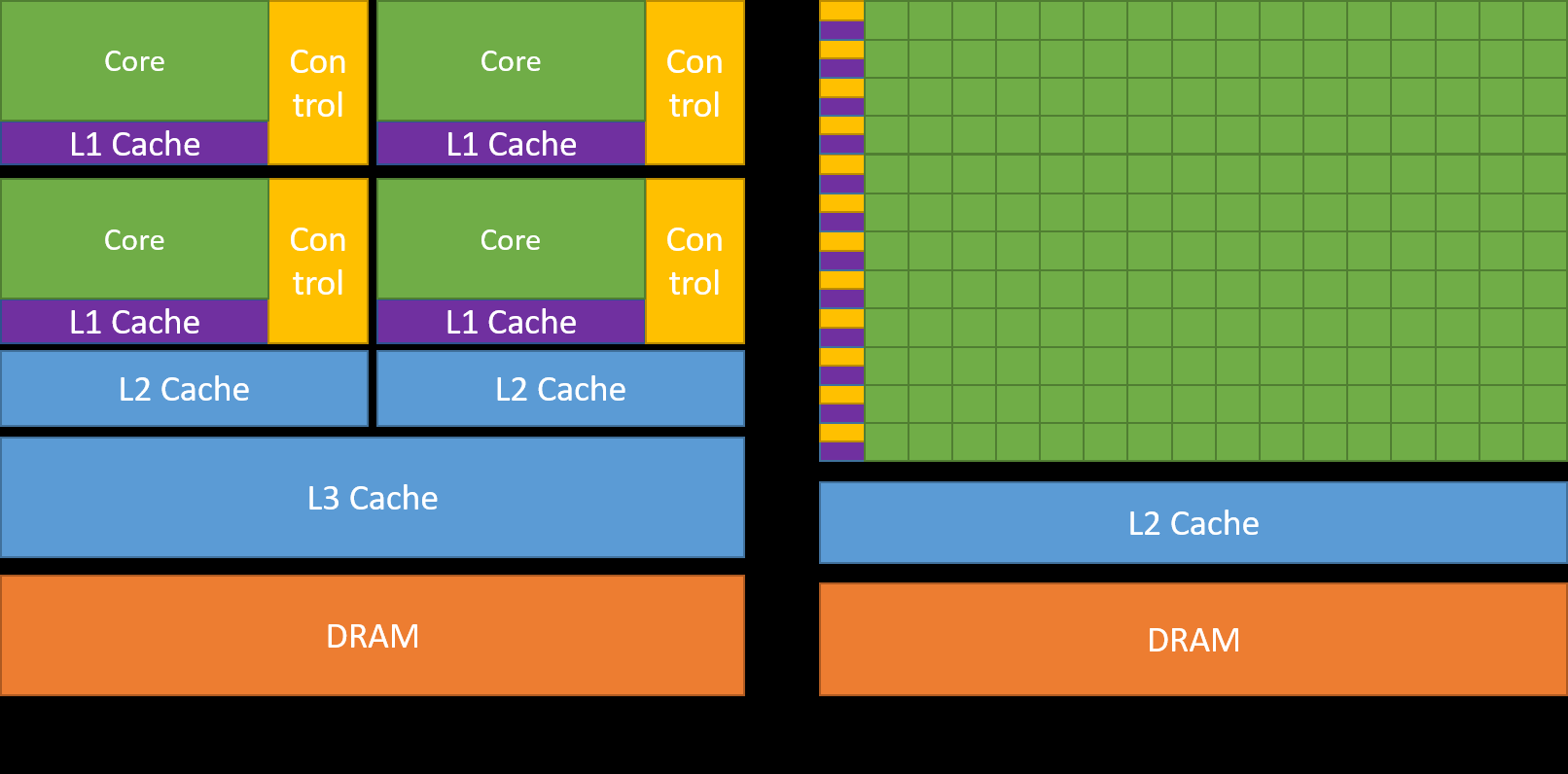
从体系结构上看,CPU 和 GPU 的区别在于:CPU 有少量“大核”,适合串行任务,GPU 有大量“小核”,适合并行任务,下图展示了 CPU 和 GPU 的体系结构差异:
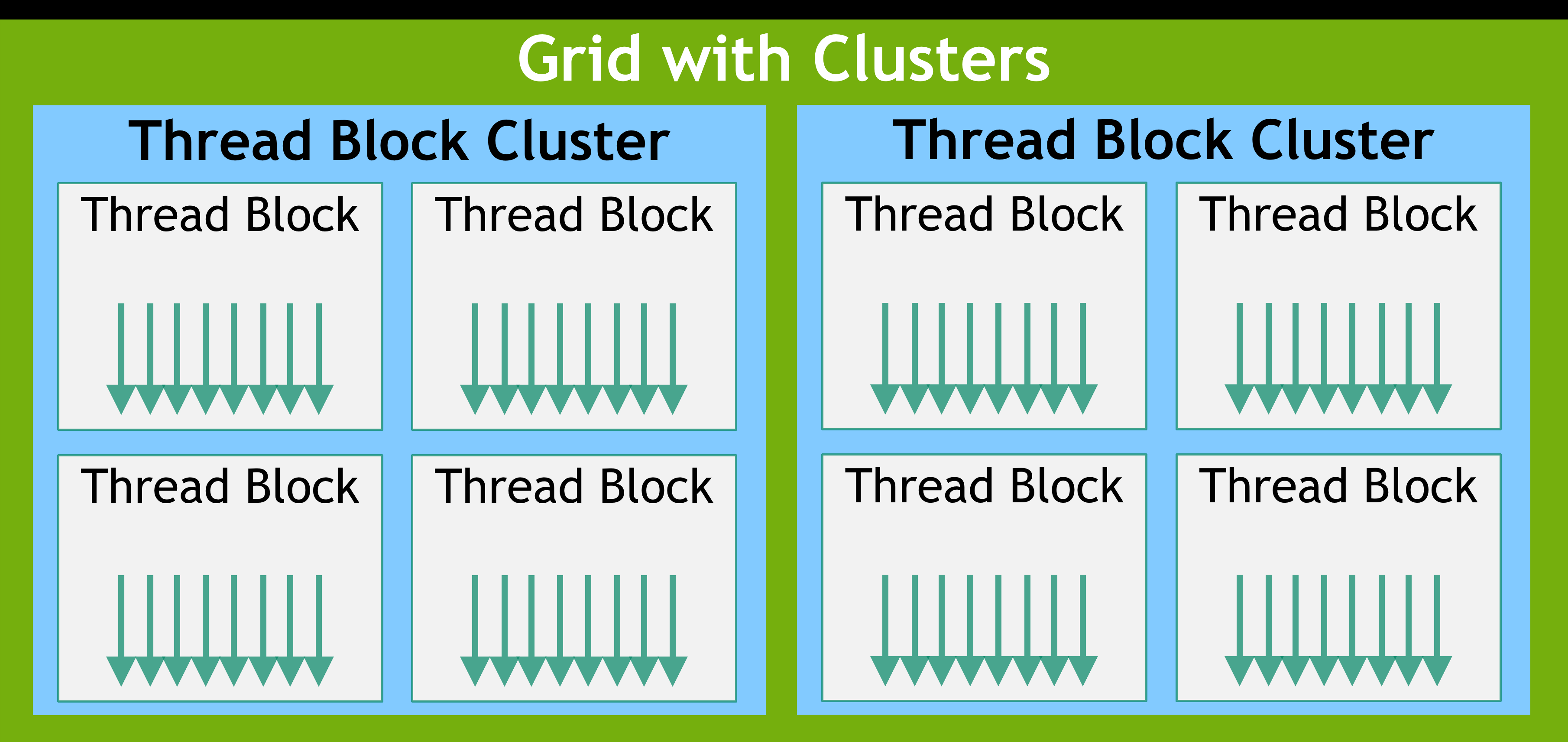
接下来看看 GPU 的体系结构:每一次 Kernel 的调用都会启动大量的 CUDA Thread,一次 Kernel 调用中的所有 Thread 称为 Grid,Grid 中的 CUDA Thread 被划分为若干个 Block,Block 中的 CUDA Thread 可以组成若干个 Warps,Warps 在指令相同时由硬件并行执行(类似于 SIMD)。

新版本的 CUDA 还有一级可选的 Thread Block Cluster
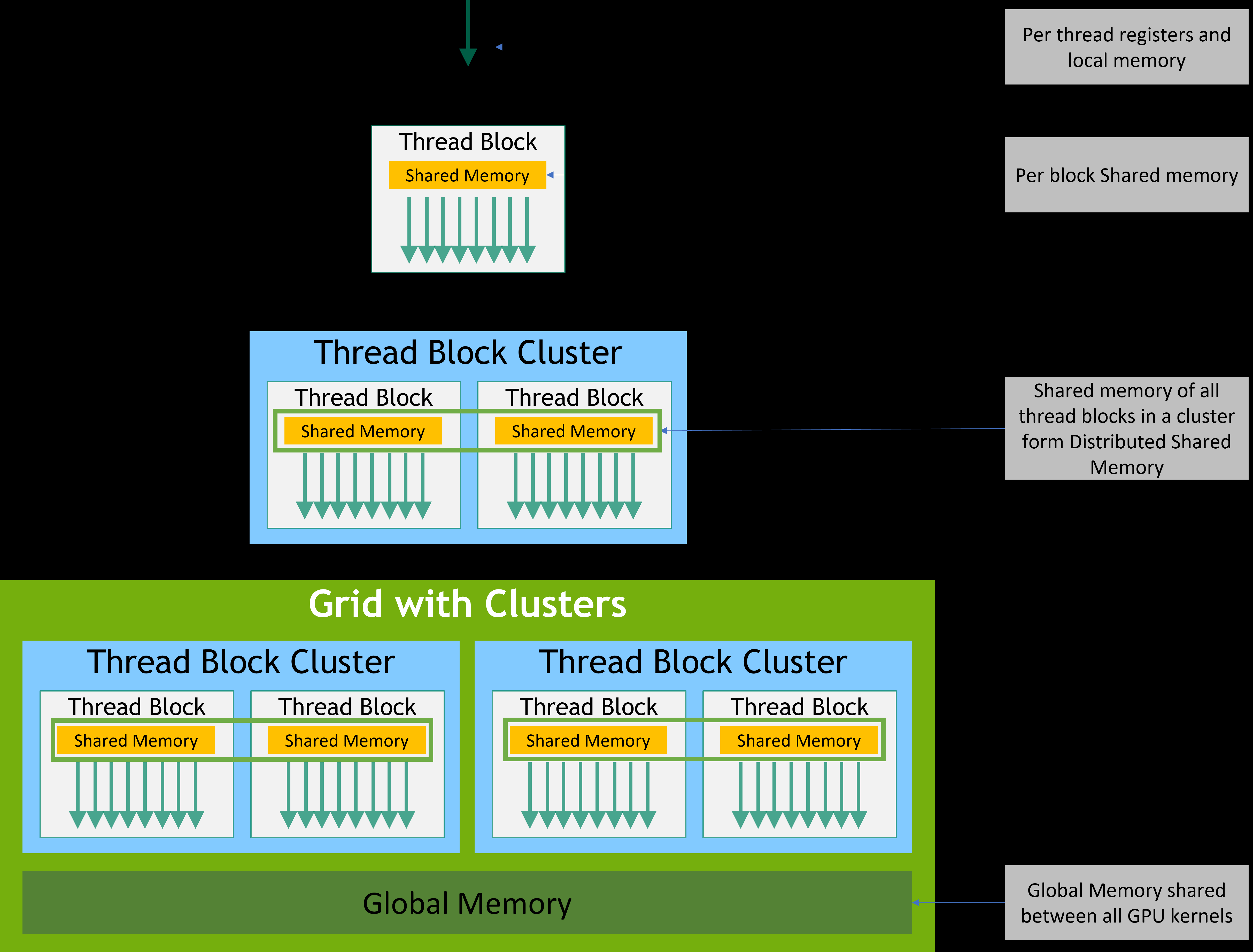
然后是 CUDA 的内存模型,类似 CPU Cache,GPU 也有有多级内存,包括 Register、Shared Memory、Global Memory 等,CUDA 编程中主要的一部分就是考虑如何利用内存局部性提升性能
最后说一下 SM(Streaming Multiprocessor):GPU 中的 SM 是一个独立的处理器,包含若干个 CUDA Core 和一组寄存器、共享内存等。每个 SM 可以调度多个 Thread Block,但是一个 SM 中的 Thread Block 不能被其他 SM 执行,所以要合理分配 Thread Block 以充分利用 SM 的并行能力。SM 基本的执行单元是 Warp(通常是 32 个 Threads),所以最好将 Thread Block 的大小设置为 Warp 的整数倍。
2 CUDA Example
CUDA 编程基本流程:
- 在 Host 端分配内存、初始化数据
- 将数据从 Host 端拷贝到 Device 端
- 调用 Kernel 函数在 Device 端执行异步计算
- 将计算结果从 Device 端拷贝到 Host 端
先看一个最简单的例子,以计算 c[i] = a[i] + b[i] 为例:
1 | // miz.cu |
编译运行:
1 | nvcc miz.cu -o miz |
CUDA 代码看上去还是很好理解的:
- 首先通过
cudaMallocManaged分配内存(这里使用了 Unified Memory,可以在 Host 和 Device 之间自动共享内存,免去拷贝的麻烦) - 然后调用 Kernel 函数
add<<<numBlocks, blockSize>>>(a, b, c, N);,这里的<<<numBlocks, blockSize>>>是 CUDA 的语法,表示启动numBlocks个 Block,每个 Block 有blockSize个 Thread。__global__修饰的函数是 Kernel 函数,可以在 Host 端调用,Device 端执行,类似的还有__device__,__host__等修饰符 - 在 Kernel 函数中,每个 Thread 通过
blockIdx.x和threadIdx.x计算出自己的索引,然后进行计算 - 最后通过
cudaDeviceSynchronize()等待 Device 端计算完成,检查结果,释放内存
这样就完成了一个简单的 CUDA 程序,至于其它具体的 CUDA 语法详细参考官方手册即可,实际还是要通过项目实践来熟悉。
可以发现,CUDA 真正困难的地方在于如何写出高效的 Kernel,这需要对 GPU 的体系结构有深入的了解,CUDA 本身代码的内容不是最主要的
3 CUDA Cheat Sheet
这里列出一些常用的 CUDA 关键词
-
__host__,__device__,__global__:修饰符,分别表示 Host 端函数、Device 端函数、Kernel 函数 -
gridDim,blockDim,blockIdx,threadIdx,warpSize:CUDA Thread 编号相关变量 -
cudaMalloc,cudaMallocManaged,cudaFree:内存分配和释放常用函数 -
cudaMemcpy,cudaMemset:内存拷贝和初始化函数 -
__device__,__shared__,__constant__:修饰符,表示 Device 中的全局变量、共享内存(Block)、常量内存 -
cudaError_t,cudaGetLastError,cudaGetErrorString:CUDA 错误处理相关 -
__syncthreads:同步函数
其余的一些常用函数和变量可以参考官方文档
References:
一些可以继续学习的资料:
- CUDA by Example / GPU 高性能编程 CUDA 实战
- Udacity CS344: Intro to Parallel Programming





