Stanford CS149 (Fall 2023) Parallel Computing
Programming Assignment 1: Analyzing Parallel Program Performance on a Quad-Core CPU
Github repo
环境配置
鉴于应该都不是 Stanford 的学生,只能本地配置环境了。我使用的是 WSL 虚拟环境,Windows 大概是不能直接用的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ~ » neofetch mizukicry@S-Terminal .-/+oossssoo+/-. mizukicry@S-Terminal `:+ssssssssssssssssss+:` -------------------- -+ssssssssssssssssssyyssss+- OS: Ubuntu 22.04.4 LTS on Windows 10 x86_64 .ossssssssssssssssssdMMMNysssso. Kernel: 5.10.16.3-microsoft-standard-WSL2 /ssssssssssshdmmNNmmyNMMMMhssssss/ Uptime: 33 mins +ssssssssshmydMMMMMMMNddddyssssssss+ Packages: 710 (dpkg) /sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Shell: zsh 5.8.1 .ssssssssdMMMNhsssssssssshNMMMdssssssss. Terminal: Windows Terminal +sssshhhyNMMNyssssssssssssyNMMMysssssss+ CPU: AMD Ryzen 9 7940H w/ Radeon 780M Graphics (16) @ 3.991GHz ossyNMMMNyMMhsssssssssssssshmmmhssssssso GPU: ceb6:00:00.0 Microsoft Corporation Device 008e ossyNMMMNyMMhsssssssssssssshmmmhssssssso Memory: 583MiB / 7560MiB +sssshhhyNMMNyssssssssssssyNMMMysssssss+ .ssssssssdMMMNhsssssssssshNMMMdssssssss. /sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ +sssssssssdmydMMMMMMMMddddyssssssss+ /ssssssssssshdmNNNNmyNMMMMhssssss/ .ossssssssssssssssssdMMMNysssso. -+sssssssssssssssssyyyssss+- `:+ssssssssssssssssss+:` .-/+oossssoo+/-.
下载 ISPC
1 2 3 4 wget https://github.com/ispc/ispc/releases/download/v1.23.0/ispc-v1.23.0-linux.tar.gz tar -xvf ispc-v1.23.0-linux.tar.gz sudo mv ispc-v1.23.0-linux/bin/ispc /usr/local/bin rm -rf ispc-v1.23.0-linux.tar.gz ispc-v1.23.0-linux
Clone 作业代码
1 2 git clone git@github.com:stanford-cs149/asst1.git cd asst1
Program 1: Parallel Fractal Generation Using Threads
生成分型图像:
1 2 3 cd prog1_mandelbrot_threads make ./mandelbrot
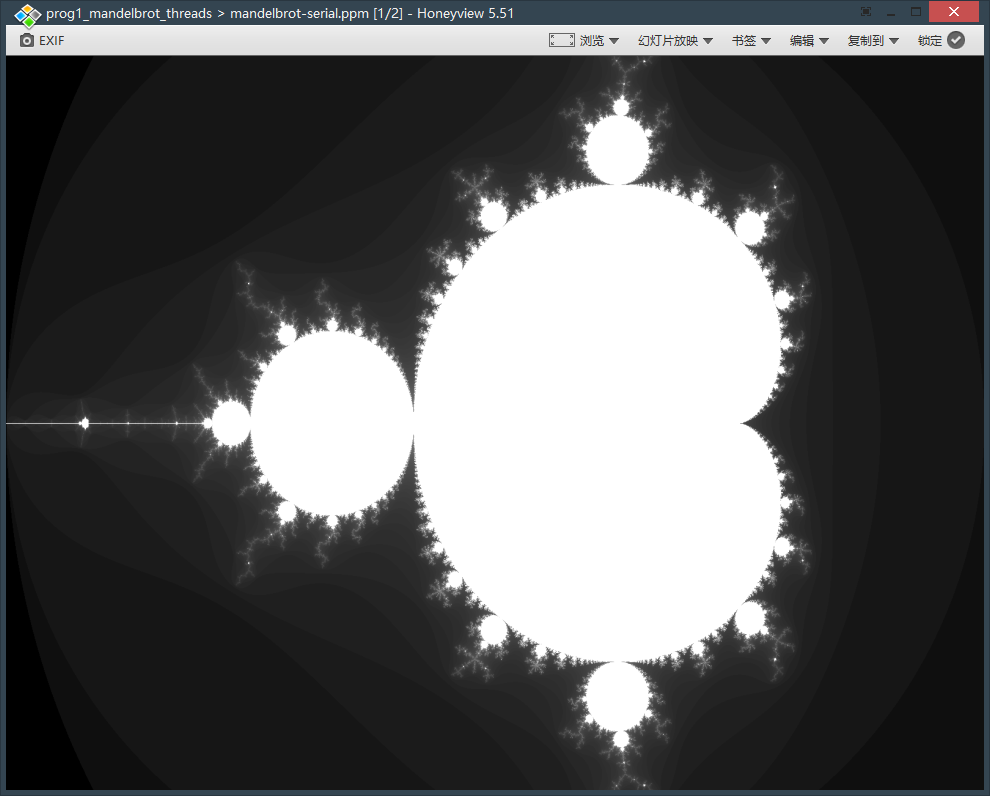
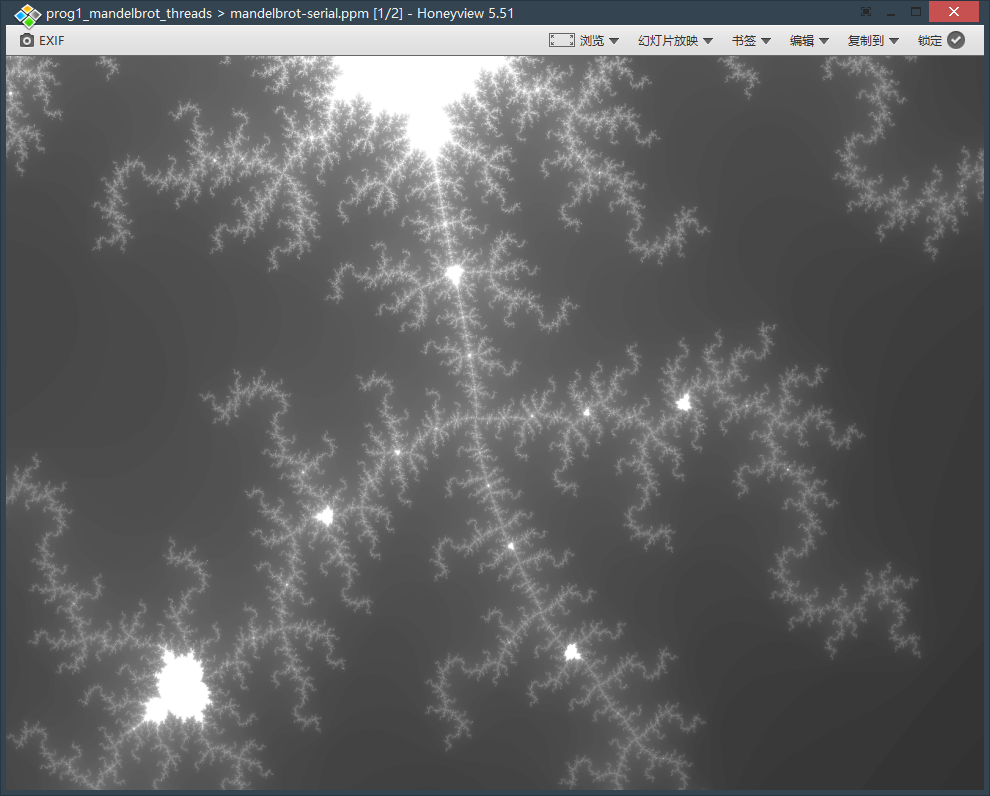
可以查看目录下生成的 mandelbrot-serial.ppm 图片,使用 ./mandelbrot --view 2 生成 Image 2
完成程序的多线程部分,对比不同线程数(2 ~ 8)的 Speedup
几行代码的事,就是把矩形等分,看懂接口就行
1 2 3 4 5 6 7 8 9 void workerThreadStart (WorkerArgs *const args) int startRow = args->height / args->numThreads * args->threadId; mandelbrotSerial (args->x0, args->y0, args->x1, args->y1, args->width, args->height, startRow, args->threadId == args->numThreads - 1 ? args->height - startRow : args->height / args->numThreads, args->maxIterations, args->output); }
修改 main.cpp 中线程数量观察 Speedup(本地 WSL 测试仅图一乐,连续 4 轮取极大值):
Threads
Image 1 Speedup
Image 2 Speedup
2
1.99
1.70
3
1.65
2.22
4
2.46
2.63
5
2.51
3.02
6
3.30
3.44
7
3.47
3.89
8
4.10
4.32
16
7.66
7.46
可以观察到 Speedup 不是线性增长,且在 3 线程时反而出现了下降。观察发现每个线程计算的时间与区域有关,像素亮度取决于计算成本,对每个线程单独计时也可以验证这一点。观察 Image 1 就不难理解为什么 3 线程的 Speedup 反而下降了
于是可以采取 Interleaved Assignment 而非 Blocked Assignment 均摊计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void mandelbrotSerialInterleaved ( float x0, float y0, float x1, float y1, int width, int height, int startRow, int skipRows, int maxIterations, int output[]) float dx = (x1 - x0) / width; float dy = (y1 - y0) / height; for (int j = startRow; j < height; j += skipRows) { for (int i = 0 ; i < width; ++i) { float x = x0 + i * dx; float y = y0 + j * dy; int index = (j * width + i); output[index] = mandel (x, y, maxIterations); } } }
1 2 3 4 5 6 7 8 9 10 11 extern void mandelbrotSerialInterleaved (float x0, float y0, float x1, float y1, int width, int height, int startRow, int skipRows, int maxIterations, int output[]) void workerThreadStart (WorkerArgs *const args) mandelbrotSerialInterleaved ( args->x0, args->y0, args->x1, args->y1, args->width, args->height, args->threadId, args->numThreads, args->maxIterations, args->output); }
Threads
Image 1 Speedup
Image 2 Speedup
2
1.99
1.97
3
3.00
2.95
4
3.98
3.90
8
7.80
7.60
16
13.95
13.60
Program 2: Vectorizing Code Using SIMD Intrinsics
使用 CS149intrin.h 中提供的类 SIMD 函数完成 clampedExpVector 函数
其实也就是照着一句一句地翻译,只是分支判断变成了位运算。不过第一次写这种东西还是有点烧脑,写得很慢
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void clampedExpVector (float *values, int *exponents, float *output, int N) __cs149_vec_float x; __cs149_vec_int y; __cs149_vec_int zero = _cs149_vset_int(0 ), one = _cs149_vset_int(1 ); __cs149_vec_float limit = _cs149_vset_float(9.999999f ); __cs149_vec_float result; __cs149_mask maskAll, mask, maskLoop; for (int i = 0 ; i < N; i += VECTOR_WIDTH) { maskAll = _cs149_init_ones(N - i); _cs149_vload_float(x, values + i, maskAll); _cs149_vload_int(y, exponents + i, maskAll); _cs149_veq_int(mask, y, zero, maskAll); _cs149_vset_float(result, 1.f , mask); mask = _cs149_mask_not(mask); mask = _cs149_mask_and(mask, maskAll); _cs149_vmove_float(result, x, mask); _cs149_vsub_int(y, y, one, mask); while (_cs149_vgt_int(mask, y, zero, mask), _cs149_cntbits(mask) > 0 ) { _cs149_vmult_float(result, result, x, mask); _cs149_vsub_int(y, y, one, mask); } _cs149_vgt_float(mask, result, limit, maskAll); _cs149_vmove_float(result, limit, mask); _cs149_vstore_float(output + i, result, maskAll); } }
结果如下:
Vector Width
Vector Utilization
2
77.6%
4
70.5%
8
66.7%
16
65.0%
结果比较显然,因为当 Vector Width 越大,其中分支不一样的概率越高,利用率越低
Extra credit: 实现一个数组求和,要求复杂度 (N / VECTOR_WIDTH + VECTOR_WIDTH) 或者 (N / VECTOR_WIDTH + log2(VECTOR_WIDTH))
很显然主要取决于最后怎么把结果加起来,log2(VECTOR_WIDTH) 显然就是每次把相邻的两个加起来减少一半,一种经典用法是手动 O ( log ) O(\log) O ( log )
1 2 3 4 5 6 7 8 9 10 11 12 13 float arraySumVector (float *values, int N) __cs149_vec_float sum = _cs149_vset_float(0.f ), v; __cs149_mask maskAll = _cs149_init_ones(); for (int i = 0 ; i < N; i += VECTOR_WIDTH) { _cs149_vload_float(v, values + i, maskAll); _cs149_vadd_float(sum, sum, v, maskAll); } for (int i = 1 ; i < VECTOR_WIDTH; i <<= 1 ) { _cs149_hadd_float(sum, sum); _cs149_interleave_float(sum, sum); } return sum.value[0 ]; }
测试的时候忘了 N 必须设为 2 的幂,试了好久一直没过()
Program 3
Part 1. A Few ISPC Basics
测试 ISPC 版本的 mandelbrot 图像生成速度
由于是 8-wide 的指令,预测 Speedup 接近 8.0,但实测 Image 1 Speedup 为 6.21,Image 2 Speedup 为 5.19。推测是由于不同实例的计算时间不同,导致部分 ALU 闲置,最终 Speedup 低于理论值
在 SIMD 指令的基础上再使用多核加速。由于每个核是独立执行,相比单核版本理论加速倍数就是核数
双核条件下实测 Image 1 Speedup 6.16 -> 11.94,Image 2 Speedup 5.20 -> 8.91。测试结果中 Image 1 结果符合预期,Image 2 加速为 1.7x,略低于预期,推测是由于 Image 2 上下图像不对称,运行时间不同
增加 task 数量可以进一步增加 Speedup。理论上 task 数量等于核数时最快,若支持超线程功能可以再翻倍
Program 4: Iterative sqrt
4.92x speedup from ISPC, 35.59x speedup from task ISPC
显然全部设成同样的值,让每个实例时间相同
1 2 3 4 for (unsigned int i = 0 ; i < N; i++){ values[i] = 2.5f ; }
6.35x speedup from ISPC, 35.29x speedup from task ISPC
观察到单核 ISPC 的 Speedup 上升,但多核基本不变,因为原本随机数据下每个核期望时间就相同
同理,交错构造,让一个 ALU 跑满,其它 ALU 闲置
1 2 3 for (unsigned int i = 0 ; i < N; i++) { values[i] = (i & 7 ) ? 1.0f : 2.999f ; }
0.92x speedup from ISPC, 7.53x speedup from task ISPC
Extra Credit: 自己通过 AVX2 指令集手动实现 sqrt
目前大多数比较新的处理器应该是支持 AVX2 的,所以本地也能做。查看 CPU 指令集:cat /proc/cpuinfo
也没啥好说的,RTFM,照着写就行
但是我是读手册苦手,找半天找不到有用的指令,最后大部分是 Copilot 帮我找的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void sqrtAvx2 (int N, float initialGuess, float values[], float output[]) static const __m256 kThreshold = _mm256_set1_ps(0.00001f ); for (int i = 0 ; i < N; i += 8 ) { if (i + 8 > N) { sqrtSerial (N - i, initialGuess, values + i, output + i); break ; } __m256 x = _mm256_loadu_ps(values + i); __m256 guess = _mm256_set1_ps(initialGuess); while (true ) { __m256 error = _mm256_sub_ps( _mm256_mul_ps(_mm256_mul_ps(guess, guess), x), _mm256_set1_ps(1.f )); error = _mm256_andnot_ps(_mm256_set1_ps(-0.f ), error); __m256 cmp = _mm256_cmp_ps(error, kThreshold, _CMP_GT_OQ); if (_mm256_testz_ps(cmp, cmp)) { break ; } __m256 newGuess = _mm256_mul_ps( _mm256_mul_ps( _mm256_sub_ps(_mm256_set1_ps(3.f ), _mm256_mul_ps(x, _mm256_mul_ps(guess, guess))), guess), _mm256_set1_ps(0.5f )); guess = _mm256_blendv_ps(guess, newGuess, cmp); } _mm256_storeu_ps(output + i, _mm256_mul_ps(x, guess)); } }
里面几个点:对于凑不齐 8 个的避免麻烦直接线性处理了,不影响性能;求绝对值的时候直接位运算操作符号位;使用各种指令时注意是否有要求内存对齐,否则会出些难以调试的问题
最后在各种 case 下都快于 ISPC,下面是随机数据的测试结果:
1 2 3 4 5 6 7 [sqrt serial]: [1202.493] ms [sqrt ispc]: [244.737] ms [sqrt task ispc]: [36.260] ms [sqrt avx2]: [221.520] ms (4.91x speedup from ISPC) (33.16x speedup from task ISPC) (5.43x speedup from avx2)
Program 5: BLAS saxpy
测试结果:0.91x speedup from use of tasks
发现多核没有性能提升,原因是程序主要瓶颈为内存读写,计算只是一条简单语句,因此多核没有效果
为什么程序中计算内存带宽是 4N 个 float 不是 3N 个 float?
考虑 Cache 的工作机制,写入到 result 时会先将内存读入到 Cache 中,修改后再写回内存,因此是 4N 个 float
只能说我实在想不出来内存瓶颈怎么解决,摸了
Program 6: Making K-Means Faster
没数据。。如果实在想做的话大概得自己造了
大概内容就是自己找 K-Means 的瓶颈然后优化,大概也是和上面的一样,就跳过了