
CMU 15-445 Database Systems Notes
开新坑.jpg
抄了抄之后感觉不如直接看提供的 Notes(
就当是强迫自己看课件用的
Lecture #01: Course Overview & Relational Model
通用数据管理系统(DBMS, Database Management System):支持定义、创建、查询、更新、管理。
Data model:数据模型,描述数据的概念的集合
Schema:模式,指定数据模型下对一类特定数据的描述
本课程重点:关系模型(Relational Model)
-
将数据存放在简单结构中(relations)
-
通过高级语言访问数据,由 DBMS 决定最佳方案
-
存储方式由 DBMS 实现
-
Relation:一个无序集合,可以看成一个 列的表(n-ary relation),每一列对应一种属性(attributes / keys)
-
Tuple:一个 元组,relation 中的每一行就是一个 tuple
-
Primary key:主键,在 relation 中可以唯一确定一个 tuple,若不指定则自动生成
-
Foreign key:外键,将一个 relation 中的一个属性映射到另一个 relation 中
一个 3-ary relation:
| Name | Sexual | Age |
|---|---|---|
| Mizuki | Male | 18 |
| Cocoa | Female | 15 |
| Chino | Female | 13 |
其中 Name 就可以作为一个 Primary key
数据操作语言(Data Manipulation Languages / DMLs)主要分为两种:
- Procedural:指定查询数据的策略(关系代数)
- Declarative:只描述需要的数据,不指定方法(关系演算)
Relational Algebra
关系代数:一系列运算符,通过指定参数将 relation 映射到另一个 relation,可以用 SQL 语句描述
- Select /
选择符合条件的数据- Syntax:
- e.g.
SELECT * FROM R WHERE id = '2'
- Projection /
投影:重排 / 筛选属性- Syntax:
- e.g.
SELECT id, name FROM R WHERE id = '2'
- Union /
求并集(要求 attributes 完全相同)- Syntax:
(SELECT * FROM R) UNION ALL (SELECT * FROM S)
- Intersection /
求交集(要求 attributes 完全相同)- Syntax:
(SELECT * FROM R) INTERSECT (SELECT * FROM S)
- Difference /
集合做差(要求 attributes 完全相同)- Syntax:
(SELECT * FROM R) EXCEPT (SELECT * FROM S)
- Product /
集合卷积:两个 relation 中的 tuples 两两组合,产生一个新的 relation- Syntax:
(SELECT * FROM R) CROSS JOIN (SELECT * FROM S)
- Join /
将两个 relation 中 tuple 两两组合,保留共同属性相同的组合,组成一个新的 relation- Syntax:
SELECT * FROM R JOIN S USING (ATTR1, ATTR2...)
Lecture #02: Modern SQL
关系代数中通常是不可重集(sets),而 SQL 中用的是可重集(bags)
建表例子:
1 | CREATE TABLE student ( |
大体结构就是 attribute name 加上 type,可以附加一些特殊标志。在表上的一个简单查询:
1 | SELECT s.name |
Aggregate functions 聚合函数
AVG(col)计算平均值MIN(col)求最小值MAX(col)求最大值SUM(col)求和COUNT(col)条件计数
e.g. 计算 gpa 平均值及相应人数
1 | SELECT AVG(gpa), COUNT(sid) |
去重可以使用 DISTINCT:
1 | SELECT COUNT(DISTINCT login) |
如果要在使用聚合函数时带上其他 attribute 可以使用 GROUP BY 语句
1 | SELECT AVG(s.gpa), e.cid |
在此基础上可以使用 HAVING 语句对 GROUP BY 进行限制
1 | SELECT AVG(s.gpa) AS avg_gpa, e.cid |
String Operations
模式匹配 Pattern Matching:通过 LIKE 语句使用
%匹配任意字符串(包括空串)_匹配任意字符
字符串连接:str1 || str2
字符串操作:UPPER、SUBSTRING 等
1 | SELECT * FROM enrolled AS e |
Output Redirection 输出重定向
- 新建表:
SELECT DISTINCT cid INTO CourseIds FROM enrolled; - 插入已有表
INSERT INTO CourseIds (SELECT DISTINCT cid FROM enrolled);
Output Control
对查询结果进行调整
-
ORDER BY排序,可以添加ASC或DESC关键字并组合1
2SELECT sid FROM enrolled WHERE cid = '15-721'
ORDER BY UPPER(grade) DESC, sid + 1 ASC; -
LIMIT限制数量,可以用OFFSET调整起始位置1
2SELECT sid, name FROM student WHERE login LIKE '%@cs'
LIMIT 20 OFFSET 10;
Nested Queries 嵌套查询
e.g.
1 | SELECT name FROM student |
此外还有如 ALL、EXISTS 等语句
Window Functions
窗口函数,用于对例如 GROUPS BY 得到的结果分别处理
Example: Find the student with the second highest grade for each course.
1 | SELECT * FROM ( |
Common Table Expressions
通用表达式,用于辅助编写 SQL 语句
1 | WITH cteName (col1, col2) AS ( |
Lecture #03: Database Storage (Part I)
Volatile Devices (Memory): 断电数据消失,支持随机访问
Non-Volatile Devices (Disk): 断电数据不消失,支持按块 / 页访问,擅长顺序读写
课程的 DBMS 基于 Disk,所以我们还需要实现文件操作。重点关注硬盘的性能瓶颈
DBMS 有一个 buffer pool 负责实现内存与硬盘间的数据交互
DBMS 为了自由度与效率,不使用 OS 的 mmap 等函数操作文件,而是自己实现
- File Storage
负责管理文件,监控操作记录及剩余资源 - Database Pages
DBMS 将数据按页(page)存储,每一个 page 有一个不同的标识(page id,可以是文件地址)。大多数 DBMS 有一个中间层用于翻译 page id。OS 和存储设备的 page size 通常为 4KB,并支持原子操作。如果 DBMS 的 page size 超过了这个大小,则需要额外操作支持原子性 - Page Layout
每一个 page 有一个 header 存放一些信息。而 page 中其他数据(tuples)的存放方式有两种:- slotted-pages
有一个数组表示所有 slot 的位置,slot 数组从前往后放,而数据从后往前,两者相遇则 page 已满 - log-structured
- slotted-pages
Lecture #04: Database Storage (Part II)
slotted-pages 的一些痛点:可能产生磁盘碎片,IO 频繁
- log-structured
- 只记录所有操作
- log 以 id 排序存入 SSTables ( Sorted String Tables)
- 有 index 支持跳转,定期压缩数据
缺点:压缩性能低
一些数据类型:整数、浮点数、定长浮点数、日期…
Lecture #5: Storage Models & Compression
-
Storage Models
- N-Ary Storage Model (NSM):将 tuple 作为一个整体插入,效率高,对于查询整个 tuple 友好,但不方便导出部分 attributes
- Decomposition Storage Model (DSM):将 tuples 分列存储。方便查询,减少 IO,但操作效率低
-
Database Compression
数据库的压缩:得到的结构应该是固定长度(变长数据类型除外),允许异步压缩,必须是无损压缩
普通的压缩算法每一次都需要重新解压 -
Columnar Compression
- Run-Length Encoding (RLE)
将一列中连续相同的值压缩为一个三元组,要求数据本身有一定的排序以优化效果 - …
- Run-Length Encoding (RLE)
Lecture #06: Buffer Pools
- Locks vs. Latches
Latch 作用于内存中,对象为线程,更轻量,Lock 作用于数据对象上。
Buffer Pool
一个 frame 数组,每个 frame 可以暂存一个 page
- page table
一个 hash table,将 page id 映射到 frame
此外还维护如 dirty flag,ref counter 等值
Buffer Pool 的一些优化:
- Multiple Buffer Pools
- Pre-fetching
- Scan Sharing
- Buffer Pool Bypass
Buffer Replacement Policies:
- Least Recently Used (LRU)
经典算法,每个元素维护最后访问的时间戳,优先替换长时间不被访问的 - CLOCK
类似 LRU,每个 page 有一个初始为 0 的值,访问则设为 1,有一个指针指向这些值,需要替换时扫描,是 1 则设为 0,否则替换
Lecture #07: Hash Tables
Hash Table
- K-V 数据结构,期望 修改 / 查询
- 哈希函数、散列方案
DBMS 的 Hash 函数通常只关心效率,不关心安全性,目前最先进的(?)是 Facebook XXHash3
- Static Hashing Schemes
Hash 表大小固定,内存用完后倍增新建- Linear Probe Hashing 线性探测
若 Hash 函数对应的位置已有值则向后遍历
删除通常使用 Lazy-Tag - Robin Hood Hashing
- Cuckoo Hashing
- Linear Probe Hashing 线性探测
- Dynamic Hashing Schemes
Hash 表可以根据需要动态调整大小- Chained Hashing
将 Hash 表的 Entry 改为链表 - Extendible Hashing
- Linear Hashing
- Chained Hashing
Lecture #08: Tree Indexes
-
Table Indexes
表索引,加速访问一个属性,但需要使用额外空间 -
B+Tree
面向磁盘,O(log(n)) 插入 / 删除
一个节点最多 M 个子节点
B+ 树的特点:- 完全平衡(叶节点深度相同)
- 除根节点以外所有内部节点至少半满
- 所有有 k 个键的内部节点有 k + 1 个非空子节点
节点中包含一个 K-V 数组,键为属性,值在内部节点中为节点指针,叶节点中为相应的数据
B+ 树具体实现:插入 / 删除 / 查询… -
B+Tree Design Choices
- 选择适当的 M(例如能够放进 CPU Cache)
- Variable Length Keys
- Merge Threshold
-
Optimizations
- Pointer Swizzling
- Bulk Insert
- Prefix Compression
- Deduplication
- Suffix Truncation
Lecture #09: Index Concurrency Control
- Locks
高层次,针对数据库某个对象 - Latches
低层次,针对某个数据结构。两种模式:读 / 写
Latch Implementations
基本原理:CPU 提供的原子指令
-
Blocking OS Mutex
OS 提供,例如std::mutex
简单易用,效率低 -
Test-and-Set Spin Latch (TAS)
DBMS 控制,如std::atomic<T>
效率较高,扩展性低 -
Reader-Writer Latches
允许并发读取,如std::shared_mutex
DBMS 需要管理读写队列,需要更多存储空间 -
Hash Table Latching
- Page Latches
- Slot Latches
-
B+Tree Latching
- Latch crabbing/coupling
基本思想:获取父节点的 Latch,获取子节点的 Latch,若子节点安全(操作不会改变形态)则释放父节点- Basic Latch Crabbing Protocol
- 搜索:从根节点向下,反复获取子节点 Latch,然后释放父节点
- 修改:从根节点向下,获取所有经过节点的 Latch,若子节点安全则释放所有祖先
- Improved Latch Crabbing Protocol
上一个基础算法在修改时基础获得根节点的 Latch,假设需要改变树形态的修改操作很少- 搜索:同上
- 修改:从根节点向下,获取所有经过节点的 Read Latch,子节点的 Write Latch。若子节点不安全则重新采用基础的算法
- Basic Latch Crabbing Protocol
- Latch crabbing/coupling
Lecture #10: Sorting & Aggregations Algorithms
Sorting
- Top-N Heap Sort 堆维护前 N 个元素
- external merge sort 磁盘上归并排序
- Two-way Merge Sort
- General (K-way) Merge Sort
- Double Buffering Optimization 预先缓存
- Using B+Trees
Aggregations
- Sorting
- Hashing
Lecture #11: Joins Algorithms
Operator Output
连接两个属性匹配的 tuple,根据实现可以得到不同的结果
- Data
- Record Ids
Cost Analysis
开销分析:Join 操作的磁盘 I/O 数量(输出结果的不计)
用到的变量:
- Table : pages, tuples
- Table : pages, tuples
Nested Loop Join
双重循环并判断,通常希望外侧 for 循环的外表尽可能小
- Simple Nested Loop Join
直接循环判断
- Block Nested Loop Join
分块,每次内层循环和多个(一个 page 或更多)tuple 比较。
- Index Nested Loop Join
为内表建立索引
Sort-Merge Join
排序后双指针合并,对有 个 buffer 的 DBMS
Sort:
Sort:
Merge:
Hash Join
为外表以属性建立 Hash 表,内表扫描时计算并查找
可以使用 Bloom Filter 优化
- Grace Hash Join / Partitioned Hash Join
对于内存放不下 Hash 表时的优化
Lecture #12: Query Processing I
Processing Models
一个数据库管理系统的处理模型(Processing Models)定义了系统如何执行查询。
- Iterator Model
迭代器模型,也称为火山模型或流水线模型,是最常见的处理模型,为数据库中的每个运算符实现了 Next 函数。
查询中每个节点调用其子节点上的 Next,直到达到叶节点,当获得一个有效 tuple 时立即 emit 返回以供父节点处理。
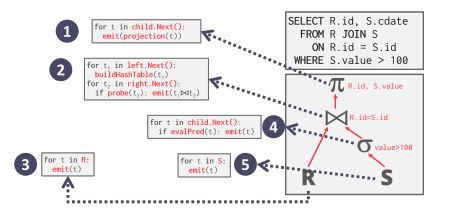
- Materialization Model
Iterator Model 的特化,每一个节点处理完所有子节点才返回。适合OLTP工作负载,不适合具有大量中间结果的OLAP查询,因为内存不够。在小查询和简单连接方面效果很好
- Vectorization Model
前两个的折中,设置最大容量,每次 emit 一个 vector
Access Methods
Sequential Scan 顺序扫描
优化方法:
- Prefetching:提前缓冲之后的 Page
- Buffer Pool Bypass:直接存入内存而非 Buffer Pool
- Parallelization
- Late Materialization
- Heap Clustering
- Approximate Queries (Lossy Data Skipping)
- Zone Map (Lossless Data Skipping)
Index Scan
通过建立的索引筛选数据
Lecture #13: Query Execution II
- Parallel DBMS:资源都在同一机器,便宜可靠
- Distributed DBMS:通信成本与失败可能性高
Process Models
定义了 DBMS 如何处理并发,DBMS 由多个 Worker 组成,负责处理不同的请求
- Process per Worker
每个 Worker 都是一个 OS Process,一个 Process 崩溃不影响其他 Worker,但对同一 Page 的多次拷贝造成开销较大,可以使用共享内存优化。
- Thread per Worker
每个 Worker 作一个 Thread,DBMS 可以完全控制 Workers,Context 切换的开销变少,不必维护内存共享模型。
Inter-Query parallelism
并发执行多个查询,具体见 Lecture #15
Intra-Query parallelism
单个查询中的并发,每个运算符都存在并行算法
- Intra-Operator Parallelism (Horizontal)
单个运算符中的并行,将数据集划分成几个片段分别操作。DBMS 使用 exchange operator 来合并子操作符的结果
- Inter-Operator Parallelism (Vertical)
- Bushy Parallelism
I/O Parallelism
- Multi-Disk Parallelism
- Database Partitioning
Lecture #14: Query Planning & Optimization
Logical Query Optimization
尽早执行过滤(predicate pushdown)、重排序、拆分 predicate(split conjunctive predicates)
Projection optimizations:
- 尽早执行投影,以减少中间结果
- 移除无用属性
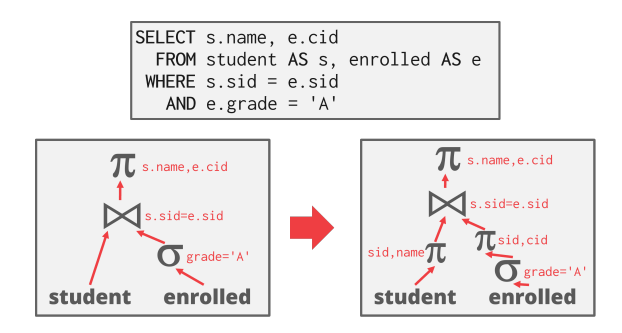
移除 / 合并不必要谓词
Cost Estimations
指标:CPU, I/O, Memory, Network
对于每个 ,维护 元组数量, 属性 中不同元素个数
Lecture #15: Concurrency Control Theory
Transaction:事务,指一系列操作,具备原子性
简单的事务系统即单线程。多线程需要保证公平与正确性。
正确性:ACID
- ACID: Atomicity
Approach #1: Logging
Approach #2: Shadow Paging
-
ACID: Consistency
-
ACID: Isolation
Concurrency control protocols: Pessimistic / Optimistic
Execution schedule: Serial / Equivalent / Serializable
SerialSchedules ⊂ ConflictSerializableSchedules ⊂ V iewSerializableSchedules ⊂ AllSchedules
- ACID: Durability
Lecture #16: Two-Phase Locking Concurrency Control
Transaction Locks
- Shared Lock (S-LOCK)
- Exclusive Lock (X-LOCK)
Two-Phase Locking: Growing, Shrinking
Deadlock Handling: Deadlock Detection / Prevention
Lock Granularities
-
Database Lock Hierarchy: Database / Table / Page / Tuple / Attribute Level
-
Intention locks
- Intention-Shared (IS)
- Intention-Exclusive (IX)
- Shared+Intention-Exclusive (SIX)
后面的笔记就不做了,感觉这么干没什么意义。





